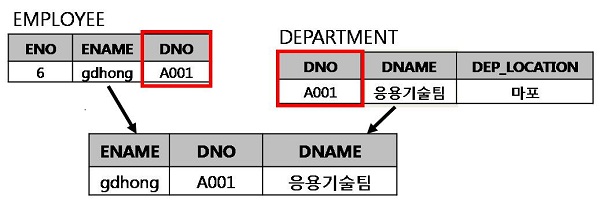
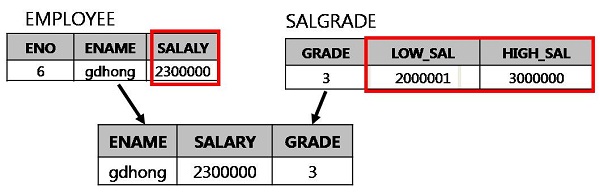
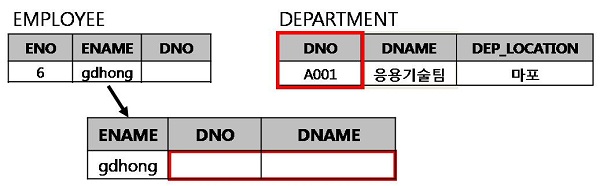
HAVING 조건
- SELECT 절에 조건을 사용하여 결과를 제한할 때는 WHERE 절을 사용하지만 그룹의 결과를 제한할 때는 HAVING 절을 사용합니다.
- 예를 들어 설명하자면 부서별로 그룹지은 후(GROUP BY), 그룹 지어진 부서별 평균 급여가 2000 이상인(HAVING) 부서번호와 부서별 평균 급여를 출력하는 경우입니다.
SELECT DEPTNO, AVG(SAL) FROM EMP GROUP BY DEPTNO HAVING AVG(SAL) >= 2000;

부서의 최대값과 최소값을 구하되 최대 급여가 2900이상인 부서만 출력합니다.
SELECT DEPTNO, MAX(SAL), MIN(SAL) FROM EMP GROUP BY DEPTNO HAVING MAX(SAL) >= 2900;

'Server > DBMS' 카테고리의 다른 글
| [DBMS_Oracle] 시퀀스 (0) | 2014.12.08 |
|---|---|
| [DBMS_Oracle] dual (0) | 2014.12.08 |
| [DBMS] Group By (0) | 2014.12.02 |
| [DBMS] NULL도 데이터이다 (0) | 2014.12.02 |
| [DBMS] 서브쿼리 (0) | 2014.11.30 |