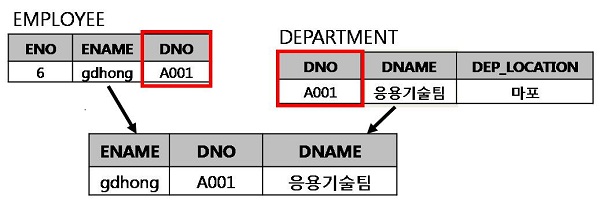
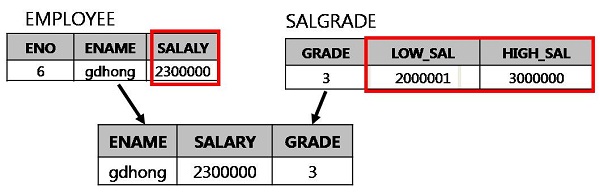
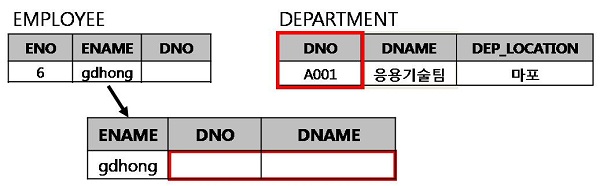
NULL도 데이터이다
DBMS에서의 NULL은 매우 중요한 데이터입니다. 왜냐하면 DBMS에서는 컬럼에 널값이 저장되는 것을 허용하는데 널 값을 제대로 이해하지 못한 채 쿼리문을 사용하면 원하지 않는 결과를 얻을 수 있기 때문입니다.
다음은 널에 대한 이해를 돕기 위해서 다양한 널의 정의를 살펴본 것입니다.
1 0(zero)도 아니고
2 빈 공간도 아니다.
3 미확정(해당 사항 없음), 알 수 없는(unknown) 값을 의미한다.
4 어떤 값인지 알 수 없지만 어떤 값이 존재하고 있다.
5 ? 혹은 ∞의 의미이므로
6 연산, 할당, 비교가 불가능하다.
- NULL은 ? 혹은 ∞의 의미이기 때문에 연산, 할당, 비교가 불가능합니다.
select ename, comm, sal*12+comm, nvl(comm, 0), sal*12+nvl(comm, 0) from emp;
- 연봉 계산을 위해 사원 테이블에서 급여와 커미션 칼럼을 살펴본 결과 영업사원이 아닌 사원들의 커미션은 NULL로 지정되어 있으므로 연봉을 올바르게 계산하기 위해서는 커미션이 NULL인 경우 0으로 변경하여 계산에 참여하도록 해야 합니다
- 오라클에서는 NULL을 0 또는 다른 값으로 변환하기 위해서 사용하는 함수로 NVL을 제공합니다. 커미션에 널이 저장되어 있더라도 널을 다른 값으로 변환하는 NVL 함수를 사용하면 제대로 된 계산 결과를 얻을 수 있습니다.
'Server > DBMS' 카테고리의 다른 글
| [DBMS] HAVING 조건 (0) | 2014.12.02 |
|---|---|
| [DBMS] Group By (0) | 2014.12.02 |
| [DBMS] 서브쿼리 (0) | 2014.11.30 |
| [DBMS] 집합연산자 (0) | 2014.11.30 |
| [DBMS] 조인 (0) | 2014.11.30 |